
Fuzzy Lookup Transformation
There was a scenario; when my friend asked me to get the email id of the people, whose emailAdrress is similar to some words, or whose email address contains words like ‘optimist’, because he wanted to give some surprise gift to those people.
When I was thinking of the solution, then I thought of to use Lookup transformation for this, but it was of no use, as it only looks for the exact matches. As I have to get the similar matches, lookup will not work. Then I thought of to use Fuzzy Lookup transformation, which displays similar results also, and that too with the matching percentage. By using this transformation, we can get several similar matches, and we can pick the one with the highest or the matches which are at least 80% similar.
For the above scenario, I followed the below steps, to make it work.
Step1: Add a DFT in your package

Step 2: Add an OleDB connection in the connection manager

Step3:
Double click on Data flow task or go to Data flow task tab, and add
One OleDb Source, one Fuzzy lookup transformation and one Excel Destination
Connect all of the above as shown below-
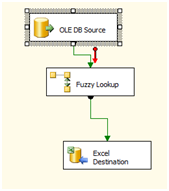
Step4: Configure OleDB source,
But before Configuring OleDB source, create a table in Adventure works Database in SSMS (SQL Server Management System 2008), as shown below and insert some records as shown below.


Then configure the oledb source with the table created above as below:

The Records in the fuzzylookup table in OleDb source, are the values which will be looked or searched in the appropriate column of the reference table. In this scenario, this table contains the 3 email address, so the above email address whether those exactly matches or similar matches, will be searched in the reference table.
Step 5: Configure Fuzzy Lookup transformation
For configuring the reference table, which is “[Person]. [Email Address]” in which the above email address will be searched (either similar or exact matches), we need to configure Fuzzy Look Transformation.
For Configuring the Fuzzy Lookup Transformation, Double click on the transformation.
Configure the Reference table tab, with the reference table, which is “[Person]. [Email Address]” for our scenario.

Go to Columns tab,
Map the email column of the Available input columns (which is the column of the oledb source table dbo.fuzzylookup) to the ‘EmailAddress’ column of the Available lookup columns (which is the column of the reference table “EmailAddress”).
Select the columns , which you want to display with the found email Address, as here , I have selected ‘email’ column and ‘EmailAddress’ column, because I want to display the email, which are searched and the emailaddress which are found as the exact or similar match of the email.

Go to Advanced tab,
Set the Maximumnumber of matched to output per lookup as 10: that means that even though more than 10 similar matches of an email are found, but in the result, it will display only 10 similar matches per email.
Set the Similarity threshold as 0.80: that means only matches which are at least 80% similar to the searched email, will only be displayed.
Token Delimiter: This is default set, as shown below. The delimiters below will break each sentence into multiple words if they found the delimiters, and then the matching will be done.

Step 6: Configure the Excel Destination,
Before configuring, create one excel file and give the columns the below column name


Do the mapping of the available input columns to the Available Destination columns of the excel destination.

Step 7: Execute the DFT.

But when you execute the DFT, and you lookinto the excel file, you don’t get the accurate result, this is because Exhaustive property (in ADVANCED Editor) is set to False by default. Set Exhaustive property to True for getting more accurate result and for comparison of all the rows.
For setting this property, Right click on Fuzzy lookup Transformation , and select ‘Show Advanced Editor’,

‘Advanced editor ‘will be displayed as below, then go the Component Properties tab and Set Exhaustive property to True.

Again execute the DFT. Now you will get the accurate results.


Each match includes a similarity score and a confidence score.
· The similarity score is a mathematical measure of the textural similarity between the input record and the record that Fuzzy Lookup transformation returns from the reference table. We can think of it as the similarity point out of 1.
If you want to know , how it is calculated, then Let me try to explain, how it is measure, as per the delimiters set in fuzzy lookup transformation, email address is broken into many words,
By considering @,-,. Are the delimiters, then, James9@adventure-works.com , is broken into 4 words, which are james9, adventure, works, com. So when ‘james’ is compared with each word, it is found in ‘james9’ , but james is not 100% similar to ‘james9’ ,so the similarity index can’t be 1. Then what it will be, it will be number of matching characters in the word/ total number of words (in james9), so it will be 5/6, which is equal to 0.833
· The confidence score is a measure of how likely it is that a particular value is the best match among the matches found in the reference table. The confidence score assigned to a record depends on the other matching records that are returned.
For example, matching St. and Saint returns a low similarity score regardless of other matches. If Saint is the only match returned, the confidence score is high. If both Saint and St. appear in the reference table, the confidence in St. is high and the confidence in Saint is low. However, high similarity may not mean high confidence. For example, if you are looking up the value Chapter 4, the returned results Chapter 1, Chapter 2, and Chapter 3 have a high similarity score but a low confidence score because it is unclear which of the results is the best match.
Point to remember:
· If the Exhaustive property (in ADVANCED Editor) is set to False, the Fuzzy Lookup transformation returns only matches that have at least one indexed token or substring in common.
Set Exhaustive property to True for getting more accurate result and for comparison of all the rows. If you set the Exhaustive property to True, the transformation compares every row in the input to every row in the reference table. This comparison algorithm may produce more accurate results, but it is likely to make the transformation perform more slowly unless the number of rows is the reference table is small.
· Only input columns with the DT_WSTR and DT_STR data types can be used in fuzzy matching.
Please provide your feedback for the post, if you find this post useful. Also Post your query or scenario, i will be happy to help.
Please provide your feedback for the post, if you find this post useful. Also Post your query or scenario, i will be happy to help.
Good..Understable
ReplyDeletesuperb
ReplyDeleteExcellent, many thanks!
ReplyDeleteThanks for the post
ReplyDeleteIt Was Very Useful For Me, Thanks
ReplyDeleteVery useful,Thanks
ReplyDeleteVery useful and well explained. Thank you for going to the trouble to post this.
ReplyDeleteVery good.
ReplyDeleteGood...!
ReplyDeleteI'm having an issue where the tables in the column tab are greyed out and the column are not showing. I cannot find anything like this on google.
ReplyDeleteVery clear. Thanks !
ReplyDeleteVery useful, thanks for explaining it.
ReplyDeleteExtremely useful. We have the need to determine similarity or "duplicates" among notes (open text) that are entered and stored in a database. We will try using the fuzzy look transform and see how far we get. Thanks!
ReplyDeleteNed
Very well explained! Thanks :)
ReplyDeleteVery well explained .Thanks!!!
ReplyDeleteHello,
ReplyDeleteI'm trying in vain to create an SSIS solution which uses Fuzzy Lookup Transformation to only return rows that have, at least, a substring match with the reference table.
For example, in the result set below, I only want to include the first two rows, since the reference column value includes the full string of the input column, 'Aaron Tilley'. The first one is an exact match so it's easy to identify with a Similarity score = 1. However, the second row is the only other one that also includes the full string from the input column, but it's hard to distinguish from the other records based on the Similarity score.
input column reference column similarity
Aaron Tilley Aaron Tilley 1
Aaron Tilley Aaron Tilley, Forbes Staff 0.7869428
Aaron Tilley Aaron Miller 0.7707121
Aaron Tilley Aaron Gulley 0.755782
Aaron Tilley Aaron David Miller 0.6520513
Is there a method, e.g. token delimiters, to identify if there is a substring match between the input and reference columns so that it's reflected in the Similarity score?
Thank you!
I feel SSIS and its components have been trending and growing ever since they came into function and this post proves it yet again with its description.
ReplyDeleteSSIS Postgresql Read